Avoid Duplication
To understand an aspect of a domain or solution, it is very often necessary to describe it from different perspectives, which requires creating Multiple views. This usually has the side effect of duplicating information. For example, when the flow of use case steps is controlled by a business rule, the same rule is typically used somewhere in the system specification as well. They both tell the same story, yet at different levels of abstraction, so they use the same business rule. Copying the rule to both specifications is a classic example of the WET anti-pattern: "Write Everything Twice", "We Enjoy Typing", or "Waste Everyone's Time". It hits the nail on the head because WET is one of the biggest sources of frustration. Instead, information should be kept in one place only and referenced from wherever it is needed. This is a universally applicable principle that has been known to the software industry for decades and can be found under various names, such as Single source of truth, Don't repeat yourself (DRY), or Once and only once.
Single source of truth (SSOT) is the practice of structuring information models and associated schemata such that every data element is stored exactly once. Any possible linkages to this data element (possibly in other areas of the relational schema or even in distant federated databases) are by reference only. Because all other locations of the data only refer back to the primary "source of truth" location, updates to the data element in the primary location propagate to the entire system without the possibility of a duplicate value somewhere being forgotten.
(source: Wikipedia)
The example above demonstrates duplication within a set of vertical views, where each view describes the same problem, just from different levels of detail. However, duplication can also exist among horizontal views, as the information might be at the same level of detail but described using different techniques. In both cases, the best way to prevent duplication is to reuse information, capturing it in a single repository and referencing it from each view. This topic is covered in more detail in Part III.
Duplications at Different Levels of Detail
The issue with describing something at various levels of detail is that the same information is stated multiple times, but each time "using different words". It is then very hard to avoid duplicating "the idea". For example, the behavior of a button can be described from the user perspective or from the system perspective:
- Level 1: "It refreshes the list of orders and displays the first 20 items."
- Level 2: "It calls API endpoint /api/orders, refreshes the tbl-orders-widget, and selects the first page."
It does not duplicate anything literally, yet when the behavior ("refreshing the orders and jumping to the first page") changes, it must be changed in both views.
A similar example is shown in the following picture. Both sequence diagrams show what happens when a product is changed. The sequence diagram on the left is a high-level overview for business stakeholders, while the right one includes technical details and is suitable for IT teams. They both describe the same thing, yet they are not identical.
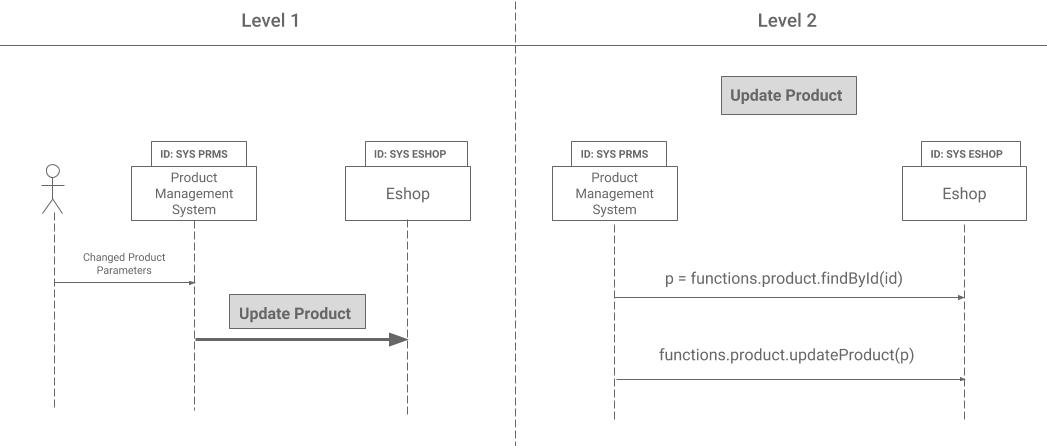
Duplication at the Same Level of Detail
Unlike the previous case, duplications of information described at the same level of detail are more explicit and can be avoided more easily. This typically occurs when the same thing is described from multiple perspectives (for example, using different diagrams), or when descriptions of different aspects share the same components. In the following picture, the purpose of the model on the left is to outline which systems are related and how, while the model on the right describes a concrete use case.
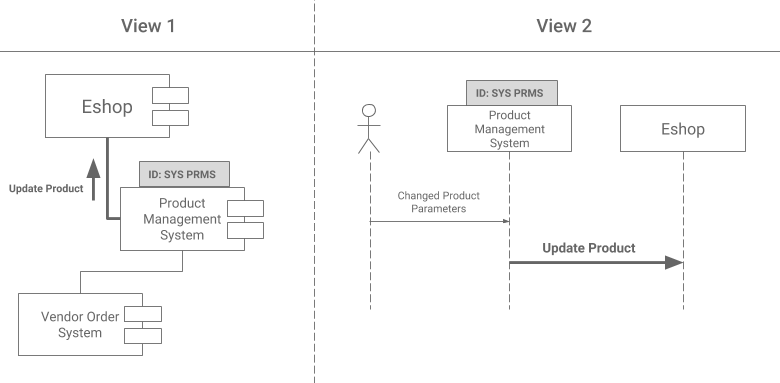
As you can see, without taking any preventative measures, we would end up with two models that share the same components. This means that if any of these components change, both diagrams need to be updated.
Minimizing Duplications
Duplicating information can never be completely avoided; we can only do our best to minimize it. The following list includes practices that help analysts avoid the most common sources of duplication:
- Don't copy information, reference it
- All artifacts are captured in the repository just once and have a unique identifier
- All artifacts have a single responsibility
- No artifact includes the specification of another artifact
Why should the artifacts not be duplicated and only referenced?
Let's take a list of systems in an organization as an example. Large enterprises operate dozens of systems and applications, and nobody knows them all. What's more, they change frequently, which often causes people to use the wrong names or struggle to understand the goal of each application. Having all systems stored in one place is beneficial because it allows you to uniquely reference them. This ensures it is always clear which system is meant, and every change automatically propagates to all occurrences.
Could anything be done not to duplicate terms?
From the Effective Analysis perspective, a term is just another type of artifact, so it should be atomic and referenceable by an identifier like all other types. This makes it easy to create a "local" project glossary by simply referencing terms from the "global" glossary without describing them over and over again. This not only saves time but also helps avoid duplication. The same applies to business rules.