Frustrated Analyst
Throughout their careers, analysts work on many projects in multiple business domains, mostly for different organizations. Joining a new company or jumping on a running project requires an analyst to quickly go through supporting materials and soak in as much information as possible in a limited time. Since this might represent a lot of information, the learning process must be top-down, going from general facts to details. Therefore, what analysts always start to look for are general domain descriptions, business and IT architecture overviews, process maps, and business terminology explanations. What they usually get, though, is a bunch of detailed documents, diagrams, and other materials, which are not interconnected and which instead confuse them.
"But the project is moving forward and has already delivered several solution components, so it cannot be that bad, right?" Yes and no. First, it is very likely that the project is not performing as well as it would if it had quality documentation. Second, during projects, people get used to using even poor documentation since they have no other choice. They learn to navigate in its clumsy structure or to recognize which parts are reliable and which are not. Also, after spending a couple of months on the project, people simply learn the terminology, processes, and systems by heart. The poor documentation does not represent a problem for them anymore since it is used on rare occasions and just to reference some complicated stuff. For example, the key process documentation could be useful even though it is buried in a document called FS20170526-A.v23 and is all described in the text, which takes 2 A4 format pages. People simply learned how to use it. However, the situation changes when the new team members join the project and want to get on board as fast as possible. The problem also arises when the process documentation is part of the overall enterprise architecture documentation, which is used by dozens of people. In this case, every minute, the bad documentation adds to their learning process, costs money, and causes frustration to those who need the information quickly.

Sources of Frustration
This section describes what we consider to be the most common reasons why people get frustrated when reading documentation written by somebody else.
Missing Documentation
Obviously, it is frustrating if critical information is not available at the right time. It is because project teams and organizations often do not keep track of what they know, which is mostly for the following reasons:
1. Documenting is a Bore
Analyzing and implementing software is fun. Creating documentation is not. It is time-consuming, and when it is not clear what to document, where to put it, and how to structure it, it is not fun at all. But we believe that documentation is usually "postponed indefinitely" not because analysts are lazy but because they do not know what to document, when to document and how to document effectively. In the following chapters, we are going to answer all these questions.
2. "It is in the source code"
In this section, we have talked about the agile approach to software development, described how it differs from the traditional processes, what are the fundamental principles and how it helps to be more productive. Unfortunately, agile is often misinterpreted. The foundation of agile, the agile manifesto, states: "Working software over comprehensive documentation". This is very often taken as "Documentation is not needed, source code is enough." But the manifesto does not say: * "Working software instead of documentation." The source code will never give an overall picture of the problem, nor will it answer why something was implemented the way it is. What is more, source code as system documentation possess also following additional limitations:
- It is undoubtedly faster to locate a model or a function overview to find out information than to search through the source code
- Source code says how the application works not why it works that way
- Source code is the lowest level, which is mostly not needed
- Source code documents just the behavior of the single system. There are also other essential parts, such as how the system is integrated with other systems, what communication flows exists between them or what data the system stores. This cannot be discovered from the source code in a reasonable time.
3. Verbal Specification
Some analysts, in good faith they are genuinely agile and that it will increase their performance, do not create any specification, so the solution development is based on what analysts told developers to build. Although it may work quite fine in specific environments, it by no means could be considered the right approach in general. It is incredibly effective to develop software this way. Still, only when the development team knows the business domain and the related systems, so they can understand and implement the changes with no or minimal specification. However, despite the working solution is the team's primary goal, it is not the only one. The secondary goal is to enable the next effort, which means allowing the others to support the solution, modify it, or extend it. This goal will inevitably require creating at least some documentation and let's be honest, will the team remember all vital information if the documentation is postponed after the project is finished? Would it not be better to capture the core facts during the development?
Besides, people supporting the solution are not the only persons who might be interested in what the team has built. There will certainly be people in the future who will need to understand the solution from the perspective of the whole enterprise. They will ask how the enterprise benefits from it or how the solution integrates or supports other enterprise components. This is why the solution documentation cannot be a solitaire and should be incorporated into the overall enterprise architecture documentation.
Outdated Documentation
The team successfully finished the project, changed two processes, added a new module to the core system, and integrated a new external service. They threw a big party because everything finally runs smoothly in production. What they forgot, though, was to update the documentation so when somebody needs to learn how the two modified processes work, they will only see the state before the project implemented the changes. They either know about the changes and will ask the team for an explanation, or in the worst case, they will rely on the wrong information.
REMEMBER
Outdated documentation is worse than no documentation.
Therefore, updating documentation must follow each activity, which has made changes to the as-is state of the enterprise.
Too Detailed or Too General Documentation
It would certainly be great to have documentation of every single aspect of the solution or enterprise in general. But as the missing documentation is terrible, the over-detailed documentation is equally bad. Once, there was a team that was very accurate in terms of the documentation. They kept the documentation very low-level, documented every detail, including SQL statements, to illustrate how the business function is implemented. They believed the more documentation they produce, the better...until things started to change. Updating extremely detailed documentation is pain, and since people do not like pains, the updates will eventually always be skipped, so what the team ends up with, is the outdated documentation.
On the other hand, many times have we been presented with the documentation that looked like this:

Documenting obvious things without any added value is wasting time. Describe a "Search Flights" button like "This button searches for flights" is not rational as it does not have any benefits for the reader. Documenting should always be balancing between the amount of information that provides the best value and the effort needed to create it and maintain it. In the next part, it will be described what types of information are beneficial and is therefore recommended to include it in the documentation.
Documentation Templates
A lot of teams try to unify the documentation outputs by prescribing what must be documented and how. This is not the right approach. Different activities require different information and forcing analysts to always write use cases, for example, implies the project ends up having a lot of artifacts that do not provide any value.
REMEMBER
One size doesn't fit all. You should always tailor the form and amount of the documentation to the given situation and audience.
Inconsistencies and Duplications
It is essential to create quality and accurate documentation that has a decent level of detail and is continuously updated. On top of that, there are additional attributes that support its readability and enable its easy maintenance. Namely, it is making the information coherent, keeping the documentation artifacts consistent, and not duplicating information. Not meeting these requirements results in the following symptoms.
Information sprinkled throughout various documents
Use case descriptions in Word documents, decision tables in the linked Excel sheet, algorithms described using activity diagrams stored in the CASE tool. Even an average-sized project requires using multiple techniques and tools producing various artifacts. However, the information should always be stored in one place, interconnected, and easy to find. Only this way, is it possible to comfortably navigate between artifacts and search in all materials with a single query.
Information stored in many different places
Duplicated information is frustrating for two reasons. First, if the information is stored in many different places, each change must be reflected in all of them. Second, if all occurrences have not been identified, different contradictory versions of single information could exist. It is then hard to find out which version is valid.
Inconsistent analysis outputs
Producing consistent outputs does not mean filling templates or creating a fixed set of artifacts for every analytical activity. Consistency in this context means unifying descriptions of all solutions or enterprise components of the same type and storing them in a similar documentation structure. It is then easy to ensure that all process descriptions include all essential information the users expect and that the readers could find the process by the standard name within the standard structure.
Incoherence
Once, we saw a team that created a screen specification that consisted of a wireframe inserted in the Word document, a list of its elements in an Excel sheet, and a list of user interface events in the form of a diagram in Visio. It was then really frustrating to need to open all three sources and put the information together to learn how the screen is supposed to look and work. Additionally, the individual parts were not labeled with an identifier, so finding the behavior of the "Save" required going through the whole list in the Excel sheet.
If it were done with the coherence in mind, all the information would be included in the screen specification or at least interconnected using identifiers. Coherence in this context means storing all related information in the single and predictable place.
Text-Only Documentation
Information can be captured in formats ranging from plain text sentences to deep diagram hierarchies. A skilled analyst must select the precise format that best suits the underlying data and the target audience. While simple bullet points are perfectly adequate for basic notes, block text is an exceptionally poor medium for describing complex, multi-conditional logic. Consider this typical textual specification of business rules:
Discounts:
- If the carrier is United Airlines and payment is made via PayPal or Visa, apply a 2% discount.
- If the carrier is United Airlines and payment is made via Mastercard, apply a 1.9% discount.
- If the carrier is American Airlines, payment is made via PayPal, and at least 3 tickets are purchased, apply a 1% discount.
- If the carrier is American Airlines, payment is made via PayPal, and no luggage is selected, apply a 1% discount.
- If the carrier is American Airlines and the departure date is 12/24, apply a negative bonus of -2%.Plain text statements like these are incredibly easy to draft, which is why they dominate introductory tutorials. However, as logic scales, text specs quickly become highly cluttered, making them difficult to parse quickly. The logic becomes overly wordy, and isolating a single rule combination is highly inefficient. Review the exact same business logic structured within a clean decision table below:
| United | American | PayPal | Visa | Mastercard | Tickets count | Departure date | Discount (%) |
|---|---|---|---|---|---|---|---|
| X | X | 2% | |||||
| X | X | 2% | |||||
| X | X | 1.9% | |||||
| X | X | $\ge 3$ | 1% | ||||
| X | X | No luggage | 1% | ||||
| X | 12/24 | -2% |
Drafting narrative text is highly tempting because it requires no formal modeling skills; you simply open a basic editor and start typing. However, this approach fails to scale. Narrative text cannot effectively handle multi-branch conditional logic, complex dependencies, or parallel events, and the effort required to maintain it grows exponentially as the system evolves.
Mixing Abstraction Levels
Review this sequence tracking a customer purchasing tickets on an e-commerce platform:
1. Customer navigates to the portal homepage and selects "Buy tickets" from the primary navigation dropdown.
...
3. The system queries inventory based on the criteria provided in the search form.
- The system queries United Airlines inventory by hitting the endpoint https://united.com/api/getTickets via a GET request.
- The system queries American Airlines inventory by hitting the endpoint https://aa.com/tickets via a GET request.
- The connection is fully encrypted over HTTPS.
...
7. Upon successful checkout, transaction data is committed to the database in the 'plane_ticket' table.
- Implementation Note: The 'provider' reference table currently lacks a designated primary key.The core failure of this specification is a complete lack of a single, defined perspective. It completely muddies abstraction levels: it simultaneously tries to define a high-level business process, dictate granular user interface interactions, and prescribe low-level technical implementation details like specific target URLs, HTTP methods, and database schemas. Consequently, business stakeholders cannot easily extract the high-level workflow because it is cluttered with code-level details, while developers struggle to isolate clean functional requirements because they are buried inside user stories. This makes the text incredibly dense and unreadable for all audiences. An analyst's primary duty is not just gathering raw facts, but structuring information so it remains perfectly coherent for different readers. This means starting with a high-level, technology-agnostic functional layer, and only then adding distinct sub-layers to isolate technical architecture, system integrations, and underlying database designs.
Obscuring the "Why"
An established software vendor delivers e-commerce platforms to enterprise accounts, and their flagship product is deployed across five massive digital storefronts. One afternoon, an executive storms into a product manager's office demanding to know why PayPal processing was completely stripped out for their second-largest client during the previous night's release.
Because each enterprise account is assigned a dedicated analyst, and the specific analyst responsible for this client resigned immediately after the release, there is no one left to answer the question. The team uncovers a brief change summary in a shared directory. It explicitly states that the client requested the wholesale removal of PayPal functionality, confirming that the system is operating exactly as designed. However, the log contains absolutely no context regarding who authorized the change or why it was initiated.
After two days of stressful cross-company investigation, they discover that the client's internal operations team had quietly decided to terminate their PayPal relationship due to fee disputes. However, they had failed to notify their own executive leadership, and the vendor's analyst had blindly executed the request without documenting the business rationale. Even the most meticulous technical specification is functionally useless if it completely fails to explain the underlying business why that drove the change.
Missing Revision History and Audit Trails
Even when teams are thoroughly trained on what information to log, oversights happen, and details will occasionally be missed. When documentation lacks context, the fallback is always to ask the person who wrote it. And frankly, few things are more frustrating than needing context and having no idea who to approach. To eliminate this bottleneck, every single modification to the documentation repository must be fully tracked, timestamped, and audited back to a specific author.
Authoring Documentation in Siloed Word Processors
Most experienced analysts have lived through this exact scenario:
- A comprehensive system specification exists and is hosted on a central network drive.
- Unfortunately, it is trapped inside a massive Word document. Embedded architecture models are compressed and unreadable, layouts break across different screens, and internal hyperlinked cross-references are broken.
- Locating specific requirements is incredibly tedious because data is fragmented across separate files: one document handles user stories, another tracks API schemas, and a third lists referenced business rules. Users must open multiple windows simultaneously across different directories just to assemble a single complete requirement.
But it gets significantly worse when desktop word processors are used as collaborative spaces. Attempting to co-author and review a single file across three or four analysts quickly dissolves into version control chaos. After a few rounds of email attachments, the team completely loses track of which file is the master copy and who introduced which modifications. While this friction can be partially reduced by migrating to cloud-based office platforms or robust enterprise wikis, desktop text editors remain completely unsuited for complex analytical modeling.
Models Devoid of Descriptions
Trading massive walls of text for clean visual models is a massive step forward. However, visual specifications become a direct source of frustration if they are built without core modeling discipline. Diagrams are meant to simplify highly complex logic that would be unreadable in plain text. Yet, very few models are entirely self-explanatory using shapes and lines alone. The vast majority of diagrams must be paired with structured metadata that defines the precise semantics of the visual elements. A model stripped of its underlying definitions is only half-usable.
Example 1
This class diagram models how customer contact records are structured in a database, showing that each customer record links to two distinct contacts:
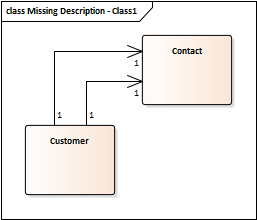
The immediate question is: why was it architected this way? Why is it capped at exactly two records? Is there a business reason for separating them into individual attributes rather than utilizing a standard contact collection? The diagram alone cannot answer these questions; it requires a supporting metadata description:
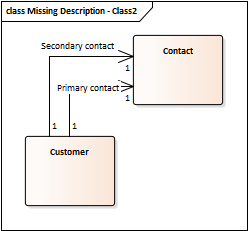
Now it is structurally clear that each customer record carries one primary contact and one secondary contact. But a gap remains: what exactly constitutes a "primary" contact, and what are the operational rules governing the "secondary" contact?
| Term | Operational Definition |
|---|---|
| Primary contact | The preferred point of contact. Used by default for all automated and manual outreach. |
| Secondary contact | The fallback contact. Only utilized if the primary contact cannot be reached after three consecutive attempts within a 2-hour window. |
With that structured glossary attached, the model becomes fully actionable. Remember: visual symbols are only half the battle; explicit semantics are what make a model useful.
Example 2
This activity diagram tracks the system logic for validating and persisting a contact record:
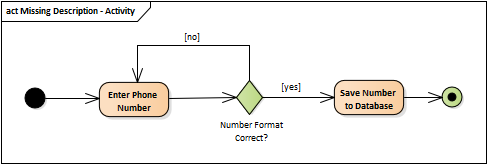
The flow logic itself is perfectly clean, clear, and unambiguous. However, as a functional specification for an engineering team, it is completely incomplete. What constitutes a valid number format? Which database schema and column are designated for storage?
| Element | Underlying Functional Logic |
|---|---|
| Number Format Correct? | Validation passes exclusively if the input string perfectly matches the regex pattern: XXX-XXX-XXXX. |
| Save Number to Database | Commits the validated string to the phone_numbers table under the number column. |
Whenever an analyst spends time drafting a visual model, they must explicitly define its intended audience and purpose, continuously verifying that the diagram delivers actionable, concrete utility to the reader.
Accepting the Realities of the Profession
The points of friction reviewed above stem from systemic issues: inexperienced practitioners, a lack of structured training, or simple corner-cutting. Correcting these underlying execution errors will naturally clean up the resulting repository. However, there are aspects of an analyst's daily workflow that can feel frustrating but are completely natural constants of software engineering. Instead of fighting them, an analyst must simply anticipate them and design their processes to accommodate them.
Continuous Requirements Evolution
Engineering teams frequently burn significant energy trying to lock down requirements permanently because mid-cycle modifications trigger rework. In reality, evolving requirements are a clear signal that stakeholders are actively engaging with the solution and thinking deeply about its utility—which is positive news. Crucially, when a business partner alters a requirement, they are stating that the underlying market value of that capability has shifted. You cannot deliver real business value if you stubbornly build against obsolete requirements simply because they were signed off in a brief. After decades of friction, the software industry accepted that requirements volatility cannot be eliminated, enshrining this reality directly into the Agile Manifesto:
Responding to change over following a plan
Many professionals claim they avoid documentation because requirements shift too rapidly to keep files accurate and consistent. We argue that this is not a problem with documentation itself, but rather a failure of the methodology and tooling used. With the right approach, a team can easily absorb changes without breaking their repository. Here are the foundational principles, which are explored in depth throughout Effective Analysis:
- Document Only Stable Core Concepts: Focus your energy on capturing foundational business logic, minimizing documentation churn.
- Document Abstract Frameworks, Not Code Details: High-level operational architecture shifts far less frequently than UI text or button placements, drastically reducing rework.
- Enforce Single-Source-of-Truth Storage: Eliminate data redundancy entirely. When a business rule lives in exactly one place, executing an update requires a fraction of the effort.
- Maintain Clean Separation of Abstraction Layers: Structuring data cleanly ensures that a localized technical update doesn't require rewriting high-level user stories.
- Leverage Automated Pipelines: Automatically compiling documentation from structured models eliminates manual editing overhead.
Documentation is Never 100% Perfect
While missing, outdated, or completely unreadable documentation causes severe drag, aiming for flawless, perfect documentation is an equally dangerous trap. Writing documentation is a secondary activity; it supports the primary goal of delivering a working solution. Sinking endless hours into chasing absolute perfection is a poor use of engineering time.
I can tolerate a map that is missing one or two streets, but I can't tolerate one that is missing three-quarters of the streets in my town.
-- Scott Ambler
It is completely fine if a specification omits the default sorting order of a minor layout, or if a label reads "Save Customer" instead of "Save Contact." It becomes a real issue only when the file completely fails to explain the underlying business purpose of that interface, or hides where the component pulls its core data from.
Eliminate the Friction
It should be an explicit goal for every analyst to design their outputs so they do not cause drag for colleagues, downstream engineers, or maintenance teams. This means capturing knowledge with clean discipline, satisfying both the immediate delivery needs and the long-term sustainability of the platform.
The subsequent sections of Effective Analysis introduce concrete practices and modeling techniques engineered to structure your analysis systematically, eliminate team frustration, and maximize delivery velocity.